??? How does one do ASM hacking in C? Aren’t those two different languages?
Well yes and no because while yes indeed those are two different languages that aren’t source-compatible, C translates to ASM and that’s the important bit.
This guide is all about revolutionizing hacking, smearing my knowledge all over your face and making Cam proud.
I’m kidding (except for the making Cam proud part). In this guide we’ll go over the following:
- How to generate both binary (object files) & verbose assembly from C files using Makefiles (as I said, we’re making Cam proud)
- How to link your binary (again, object files) to the game ROM using EA/lyn.
- Various ways of linking the game to your C (making headers, linking to “reference objects” and/or abusing EA definitions)
- How to mix ASM & C for complex hooks & hacks
- Some more Makefile shenanigans
This guide is not about teaching C. I’m fairly certain that the rest of the internet has that covered. (Just search for “C Tutorial” on DuckDuckGo).
This guide assumes you are familiar with GBA assembly and the ways we use it in the context of GBAFE hacking. I suggest you read Tequila’s amazing guide to exactly that if you aren’t.
Getting Started
Quick introduction to object files
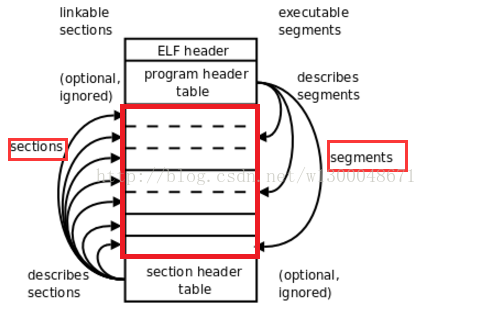
You know what an elf is? No, not the fantasy race. I meant the file format. If you do, you either are an experienced computer scientist (and you might not need to read any of this), or you read my lyn thread where I tried to explain what those were and got confused because I failed to do so.
ELF (Executable Linkable Format) is a file format. It is one of a number of formats that can be used to encode object files, and the one we are going to be using here. For the sake of me being stupid, I sometimes refer files that follow that format as “an elf” (or even worse, “elves”).
To put it in a very simple way, object files are annotated binary dumps. The “annotations” are things like symbols (putting names on locations within the dump), relocations (defining where references to outside symbols are within the dump), sometimes debug information, and sometimes more information helping linkers do their job.
If you have been ASM Hacking before, possibly using an utility script called something like “Assemble ARM.bat”, you already indirectly messed with object files. What a typical “Assemble ARM.bat” does is call the assembler (as) which generates an object file, and then call an utility (objcopy) to extract the binary part from it (ignoring all that potentially useful annotation stuff).
This works well enough for assembly: We have absolute control on the layout of the binary file, so we can just know where stuff is (relative to the beginning/end of it). For example, when we need to call the first (and often only) routine contained in the binary, we just use the address of where we inserted it.
But when we want to start messing with higher level languages, we loose that control, so we have to make use of other means know where things are. Those means being brought to us through those object files (and those precious annotations).
Note: Using object files isn’t restricted to C hacking, you can also make use of them with regular ASM, as some hackers do, or even use object files for just data, as you can do with songs.
(Re)Installing devkitPro/devkitARM
Note: the devkitPro tool installation process has changed a lot since I first wrote and posted this. I would rewrite this to fit the new process but I can’t get it to work on Windows and I’m not quite in the mood of messing up my install on Linux. So hopefully you can get enough information on the web on how to install the thing.
For Windows, see the installer.
For everything, see the devkitPro pacman stuff.
Compiling for the GBA
Before working on your new crazy battle animation system that revolutionizes hacking, we’ll start simple.
We are going to write a simple piece of C code and compile it to GBA ASM. But we want to do it properly, while monitoring each of our steps carefully.
Code
Find yourself a folder somewhere in which you will be doing all of this, and create a new empty text file with the .c extension. Don’t try anything fancy with the name (and avoid spaces), something like test.c should do. Paste the following in it:
/*!
* Sums an arbitrary range of ints stored contiguously in memory.
*
* @param begin pointer to the first element of the range
* @param end pointer to past the last element of the range
* @return the sum of all int values in the given range
*/
int sum_range(const int* begin, const int* end) {
int result = 0;
while (begin != end)
result = result + *begin++;
return result;
}
As I said, I’m not here to teach C. Hopefully the code and doc should speak as to what this does. The focus here is to make this work in the context of a ROM hack.
Compilation
Compile your file with the following command:
PATH=${DEVKITARM}/bin:${PATH} && arm-none-eabi-gcc -mcpu=arm7tdmi -mthumb -mthumb-interwork -Wall -Os -mtune=arm7tdmi -S <myfile>.c -o <myfile>.asm -fverbose-asm
Actually don’t do that. That would be messy and ugly. Instead: let’s keep our promises of making Cam proud, and use Makefiles.
Makefiles are relatively simple things: they are files that define how to make other files via rules. Those files are interpreted by a program called make (in our case, it’s specifically the GNU make variant).
DevkitARM for the GBA comes bundled with a bunch of useful bits of makefiles to include in ours (in addition to actual templates for making fully custom homebrew ROMs but we aren’t here for that), so we will gladly borrow one of them ($(DEVKITARM)/base_tools) and include it in ours. It will define all the locations of the DevkitARM developement tools, which includes the ones we are interested in (most notably the C compiler via $(CC) and the assembler via $(AS))
Here’s what we’ll start off with:
.SUFFIXES:
.PHONY:
# Making sure devkitARM exists and is set up.
ifeq ($(strip $(DEVKITARM)),)
$(error "Please set DEVKITARM in your environment. export DEVKITARM=<path to>devkitARM")
endif
# Including devkitARM tool definitions
include $(DEVKITARM)/base_tools
# setting up compilation flags
ARCH := -mcpu=arm7tdmi -mthumb -mthumb-interwork
CFLAGS := $(ARCH) -Wall -Os -mtune=arm7tdmi
# C to ASM rule
%.asm: %.c
$(CC) $(CFLAGS) -S $< -o $@ -fverbose-asm
# C to OBJ rule
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
In your folder, next to your .c file, create a new text file called Makefile (no extension!) and paste all of the above in it.
Important Note: the characters before the $(CC) stuff (the recipes) are not a bunch of spaces, but rather tab characters (on your keyboard it’s probably on the far left over the caps lock key). If when copy-pasting you get spaces instead of tabs, replace them. This also applies to other snippets of makefiles I’ll give you later.
This makefile defines how to make two things: .asm files from .c files, and .o files from .c files. It isn’t very “complete” yet, and I’m voluntarily omitting details on what this means (that’s what the “Advanced Makefile Shenanigans” section is for), but it will do for now.
Now to run the actual make program.
Windows
Make sure msys is in your path! A quick way of checking your path is by opening the command line (dw that won’t be the last time) and type echo %PATH%.
Anyway, in explorer, Shift+Right Click on the folder your files are in, and select “Open command window here” (easier than to open cmd and manually cd to it).
In the command window, simply type make <myfile>.asm, where <myfile> is the name of your .c file, without the .c.
It should output something like arm-none-eabi-gcc -mcpu=arm7tdmi -mthumb -mthumb-interwork -Wall -Os -mtune=arm7tdmi -S <myfile>.c -o <myfile>.asm -fverbose-asm, and be done. Then you should have a new <myfile>.asm file. yay!
To build an object file instead of an asm file, type make <myfile>.o instead.
Linux/other unix
Open terminal, goto folder, type make <myfile>.asm (where <myfile> is the name of your .c file, without the .c) or make <myfile>.o. Same as for Windows, expect you don’t need no msys since you already have the whole unix thing natively.
The Generated ASM
Let’s open <myfile>.asm and Woah what a mess. There’s a lot of useless junk. I have like 45 lines of just it listing me all the compiler flags that were enabled… Let’s just ignore all that and get to the actually interesting thing.
If I ignore all the superfluous things and aerate (?) a bit, I get this:
sum_range:
movs r3, r0
@ <myfile>.c:9: int result = 0;
movs r0, #0
.L2:
@ <myfile>.c:11: while (begin != end)
cmp r1, r3
bne .L3
@ <myfile>.c:15: }
bx lr
.L3:
@ <myfile>.c:12: result = result + *begin++;
ldmia r3!, {r2}
adds r0, r0, r2
b .L2
(I say “I” because you may get a slightly different output, since you may not be using the same version of gcc as I do, and the output may differ)
Well what do we have here? That’s good old assembly! Pretty well optimized asm at that. In fact you may have noticed it in the CFLAGS Makefile variable that I set the -Os gcc option, so the generated asm should be fairly optimally small. If you’d rather use -O2/-O3 or something else, feel free to do so! (maybe even try them all out and compare the outputs).
Anyway, the generated asm looks like it does what the C function we wrote before also does. Neat. That was the plan. You can even see what line of C corresponds to which bit of asm (that would be thanks to -fverbose-asm), which is useful for debugging (especially since we don’t have access to source-level debugging with EA as of now).
So we learned how to get ASM from C. Now it’s time to try and put that to use.
Hacking the game
Ok so that’s the tricky part. Before this, we were kinda doing our thing in our corner and messing around with tools. But now it is time to jump back into the fantastic mess of a world that is ROM Hacking.
As far as I know, those are the common methods of linking an object file to a GBA ROM:
-
Dumping the binary from the object and inserting it directly (the good old “Assemble ARM.bat” method I already went on, again, no way of knowing how the binary is layed out, so pretty limited). This method has the advantage over the other two methods of being extremely simple (as we’ll see when we get to it).
-
By Setting up complex linker scripts that basically build the ROM either from split parts of the original and your own hooks and things or by other hacky means. I don’t have much knowledge about that method, but @MisakaMikoto has posted some interesting resources on that in the replies below.
- Once the
FE8 Decompilation Projectcomes to the point where everything is relocatable, this method (or something very similar to it) will suddenly become much more better yes.
- Once the
-
Using Event Assembler &
lyn. Event Assembler has already proven itself as a powerful yet accessible tool for ROM Hacking, andlynis the interface EA has to object files. (It’s probably obvious that, as both the developer oflynand one of the maintainers of EA I might be just a bit biased towards this method lol). That’s what we are going to be doing in this guide.
Dumping the binary
Before getting to the interesting part, let’s get that method out of the way. It’s not a very good idea to use it for C hacking imo, but since it’s so easy I may as well demonstrate it anyway.
# OBJ to DMP rule
%.dmp: %.o
$(OBJCOPY) -S $< -O binary $@
Add that to the end of your Makefile, and then all you need to do is make <myfile>.dmp, and then you can insert this wherever.
(Note how this shows that you can chain rules in makefiles, since here it has to do file.c => file.o => file.dmp, and can do all that in one make call).
Note that the sample code I gave you above does work with this method, since the generated ASM is the first (and only) thing in the binary.
By using Event Assembler & lyn
NOTE: From now on, I’ll be assuming you are hacking FE8, since for testing I’ll be messing with event slots (because those are just the best thing ever). The actual addresses will be for FE8U, so you’ll have to find it yourself for FE8J (or FE8E).
Ok so, to put it simply, lyn takes an object file and makes EA code from it.
Let’s take the the object file from before (<myfile>.o, remember?).
$ ./lyn <myfile>.o
We get this:
PUSH
ORG (CURRENTOFFSET+$1); sum_range:
POP
SHORT $0003 $2000 $4299 $D100 $4770 $CB04 $1880 $E7F9
What is that? Well, we see sum_range, which is interesting, since it’s the name of our function… But it’s defined at CURRENTOFFSET+$1… +1? Well that’s because of the thumb bit. Indeed since our function was written in thumb, the symbol that refers to it also holds the thumb bit (this also means that we don’t have to add it when refering to the symbol elsewhere, which can be confusing since that is what we used to do with binary dumping).
So the symbol (label) to our function exists within EA? That’s already better than what we had with the dump method, where only the binary was left.
Speaking of binary, what’s those numbers? Well everyone probably guessed it’s the actual assembled assembly. You can check: each short correspond to an opcode (Unrelated Note: instead of using add r3, r0, #0 to encode mov r3, r0, which is what as would do, gcc uses lsl r3, r0, #0. Funky stuff!).
Let’s test our thing! To do that we’ll simply use the context of an ASMC event since that’s easy to write. But first we need an ASMC-able function. Let’s add that to the end of our .c file.
static int* const sEventSlot = (int* const) (0x030004B8);
/*!
* Sums event slots 1 through 4 and stores the result in slot C.
*/
void asmc_sum_slots(void) {
sEventSlot[0xC] = sum_range(
&sEventSlot[1],
&sEventSlot[5]
);
}
This will call sum_range for the values in Event Slot 1 to 5 (5 excluded, so [Slot1] + [Slot2] + [Slot3] + [Slot4]), and store the result in Event Slot C.
We’ll use these test events:
SVAL 1 1
SVAL 2 2
SVAL 3 3
SVAL 4 4
ASMC asmc_sum_slots // call asmc
SADD 0x0C3 // r3 = sC + s0
GIVEITEMTOMAIN 0 // give mone
// NoFade
// ENDA
We should be getting 1 + 2 + 3 + 4 = 10 gold at the end of it.
Anyway, here’s the lyn output:
PUSH
ORG (CURRENTOFFSET+$1); sum_range:
ORG (CURRENTOFFSET+$10); asmc_sum_slots:
POP
SHORT $0003 $2000 $4299 $D100 $4770 $CB04 $1880 $E7F9 $B510 $4904 $4804 $F7FF $FFF3 $4B04 $6018 $BC10 $BC01 $4700
BYTE $CC $04 $00 $03 $BC $04 $00 $03 $E8 $04 $00 $03
Note that both functions have corresponding symbols, the usefulness of having linking is already showing itself.
Anyway, put the test event somewhere in a chapter (with easy access, we really don’t need to make our life harder), put the lyn output somewhere outside of chapter events, assemble & run to see the result.
Yay! It worked! Or at least I’ll assume it did for you, since it did for me. I indeed got 10 gold from the event.
So that’s it I guess! You made a C hack. From now on, I’ll be going over more isolated topics, which will cover some more advanced parts & tricks that can be useful when hacking in C.
lyn in the makefile
I’m a bit less hurried about this one, since this one requires a bit more setup. Indeed since lyn is probably not in your path, you either have to put lyn in one of the folders in your path (I’d recommend against that personally), add a folder with lyn in it to your path from the makefile (so the modified path is only in effect during make invocation), or directly reference lyn from the full path to the binary (better done through a make variable). We’ll do the latter.
In your makefile, put the following somewhere before the rules (say, after include $(DEVKITARM)/base_tools):
# defining path of lyn
LYN := $(abspath .)/Tools/lyn
Then, in the folder where the makefile is in, make a subfolder called Tools, and put the lyn binary in it (and make sure it’s called lyn or lyn.exe (depending on your system)).
Now for the actual rule, add this at the end of the makefile:
# OBJ to EVENT rule
%.lyn.event: %.o
$(LYN) $< > $@
Now you can make <myfile>.lyn.event, and you’ll get that sweet lyn output in, you guessed it, <myfile>.lyn.event.
I’m choosing to generate files under the “double” extension .lyn.event to differenciate generated events from hand-written events. This is the same reason I’m using .asm instead of .s for asm generated from .c.