Hello, I am new here and am trying to create a simple project with FeBuilder. I was curious as to whether or not you could have a character’s portrait change, similar to Alm and Celica gaining new portraits when they promote in Shadows of Valentia.
By default, there are restrictions, but not impossible.
You can display portrait ID + 1 by setting the “0x00800000 Increase portrait index by 1” flag to the status flag of the RAM Unit structure.
Set this status flag with the event instruction using the FE8-Set Condition patch.
If you want to change more than this, there is no way to write ASM yourself.
Alright. I’ll try messing around with that. Thanks!
Hi! I’d been looking to potentially download this a little while ago. When I went back to it today though, the link that had previously had all of the “how to download” instructions seems to be just bringing me to this, and I wanted to see what’s up (or if something’s messed up on my end):
I made a routine that allows you to freely change portraits.
「Switch Portrait images by class, chapter, flag.」
It is included in the patch of the latest version of FEBuilderGBA.
2 Likes
I fixed the problem.
The wiki is supported by SSL.
However, it seems that there is a problem that the administrator of the wiki is misconfiguring the URL transfer setting, and it has not been successfully transferred from http to https.
I switched all the links manually from http to https.
You should click this link here scroll down and you should click this thing here

Well that’s how i downloaded builder anyway
I’m trying to make a custom class that uses both Swords and Magic but when I try to use the it the animation are broken and this message appears:

Any thoughts on how to solve it?
1 Like
How about trying “Limit Weapon Rank Display” patch?
If you ask me to fix your ROM problem, please attach report.7z.
Is there any way of removing the effects of the Modern Growth Byte or is it only possible by going in to every single character/class and editing each?
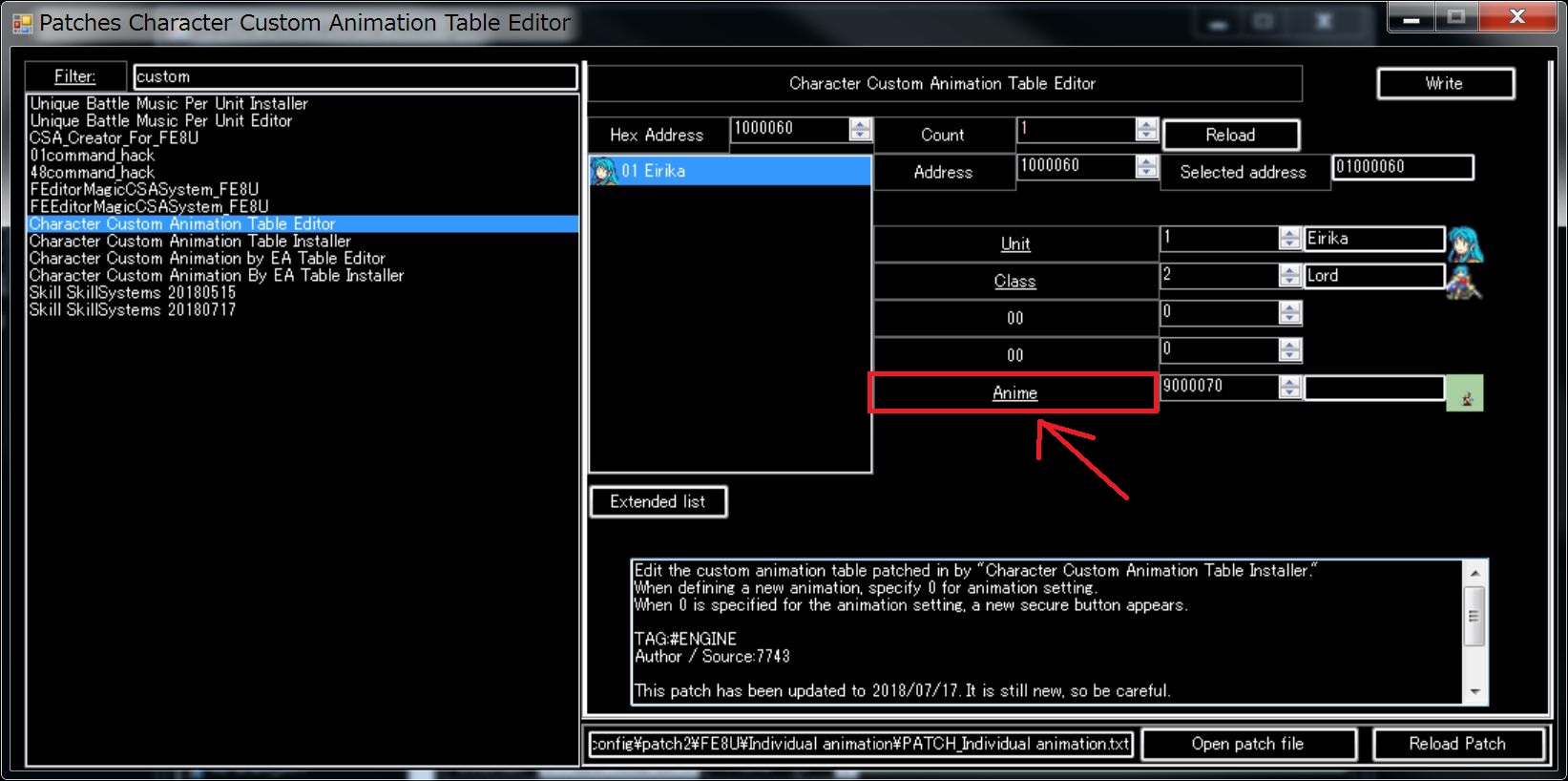
How do I use the character custom animation table editor properly for FE8? I set the animation value to 0, secured the data, but then i don’t know what to do after that. I can set one animation but I don’t know how to set animations for multiple weapons for just one character
what is “Modern Growth Byte”?
Please explain a little more concretely what you want to do.
Does “character custom animation table” say things to this part?
Or are you talking about Custom Animation Patch?
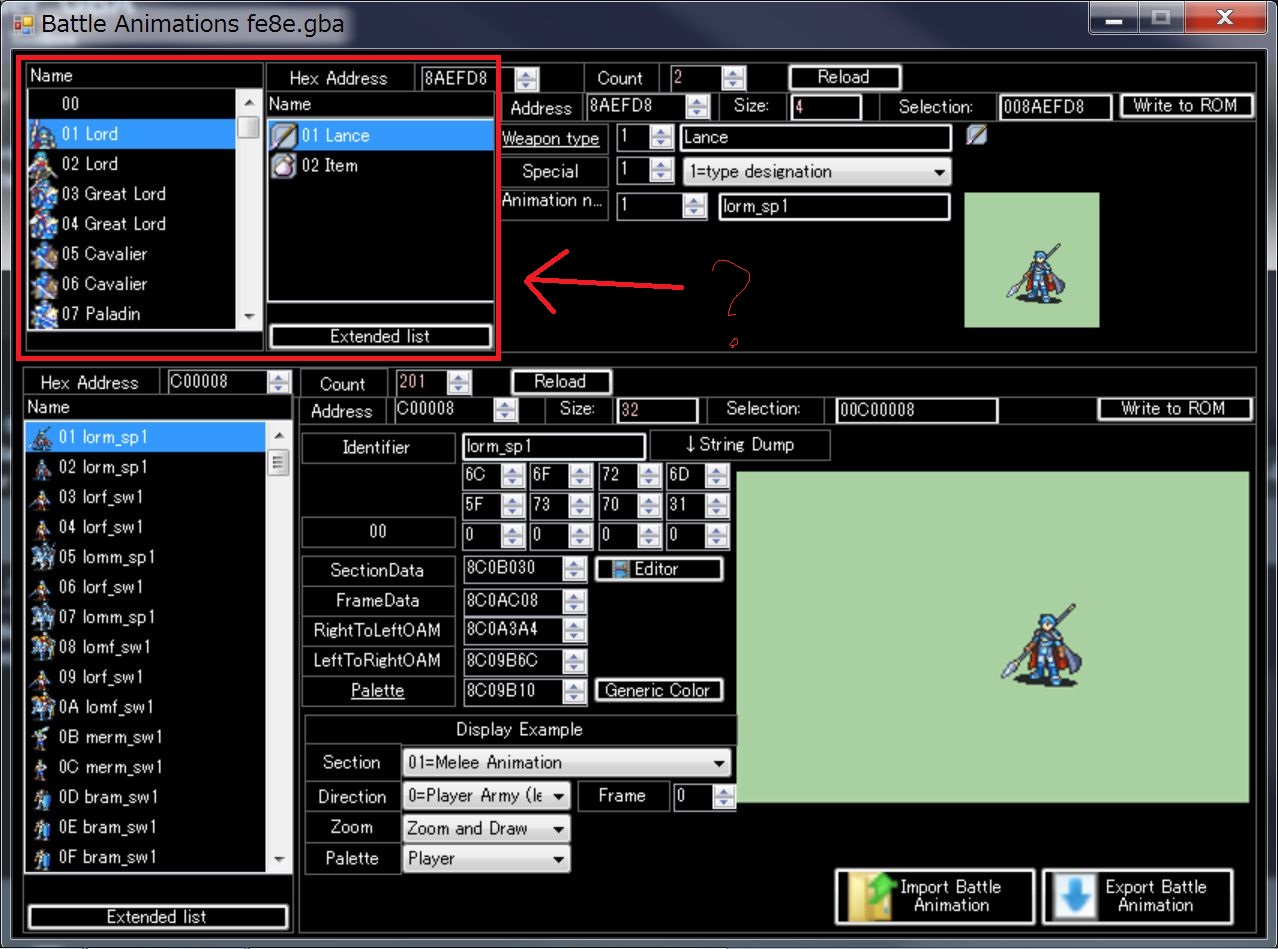
Perhaps, you seem to be talking about the Custom Animation Patch.
After securing space, please click the link of Anime.
Then you will see this screen, so please make settings for each type of weapon and each special weapon.
In existing, there is two motion, has sword motion and no weapons motion(item).
If you want to set a lot more, please click on the Extends List enclosed with a green frame and secure additional space.

Normally, class battle animation refers to pointer of class setting.
The Custom Animation Patch will overwrite the specified pointer on the condition specified by you.
Therefore, different animations can be displayed under specified conditions.
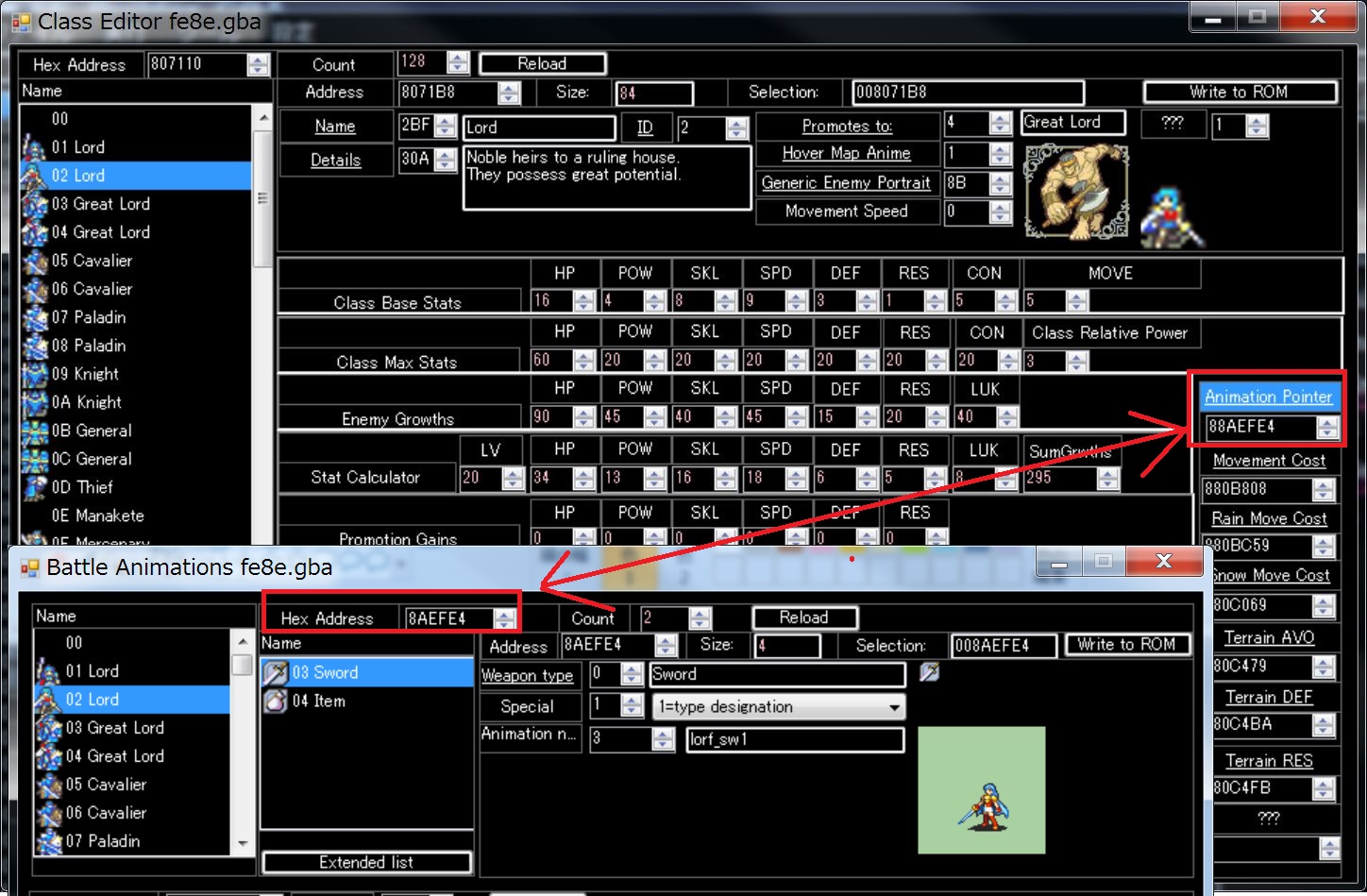
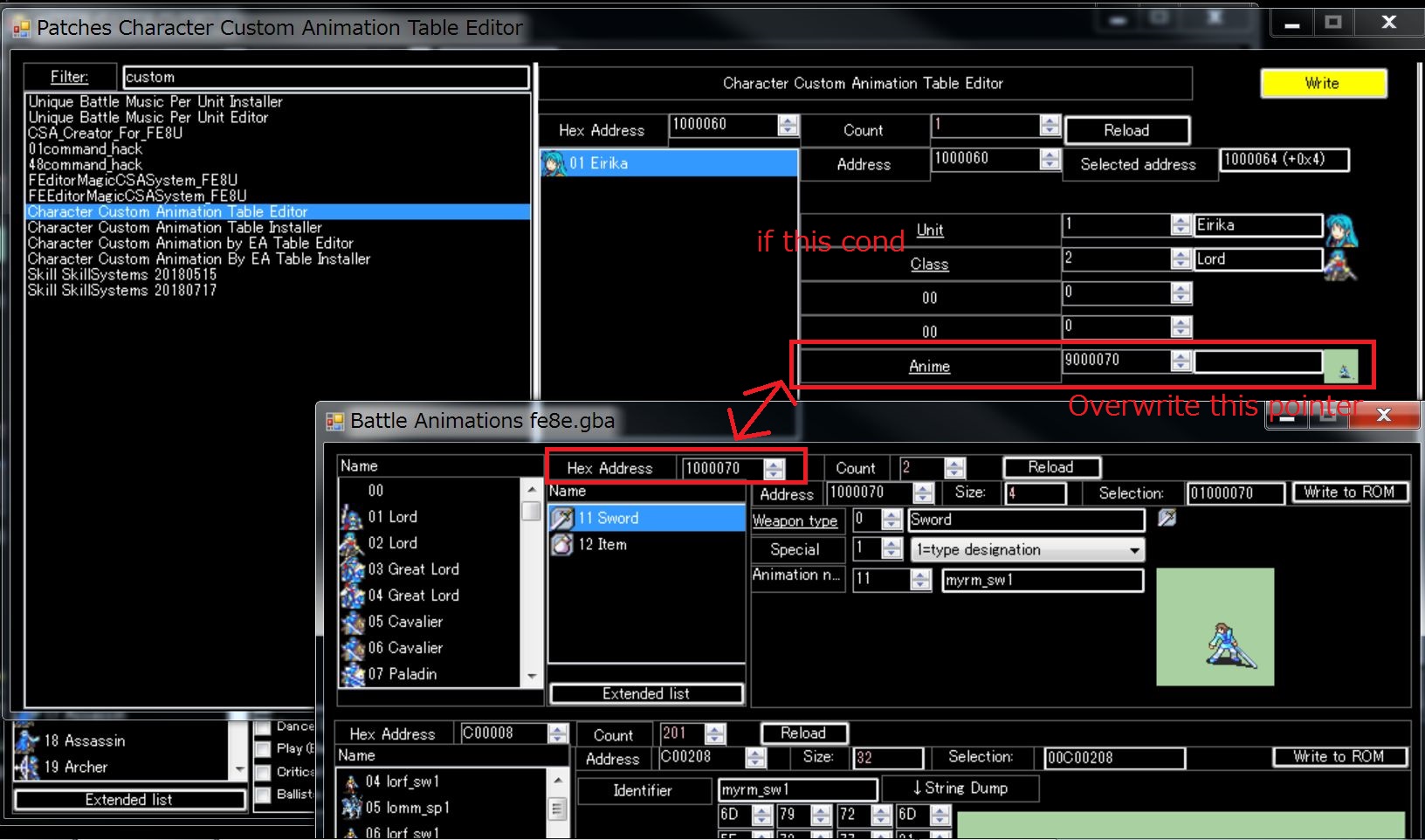
For example, if you have two SwordMaster, you want to assign a dedicated SwordMaster animation to one unit.
When I read your post, I thought like just wanting to change the animation in certain weapons.
If that is the case, I think that it is possible without using Custom Animation.
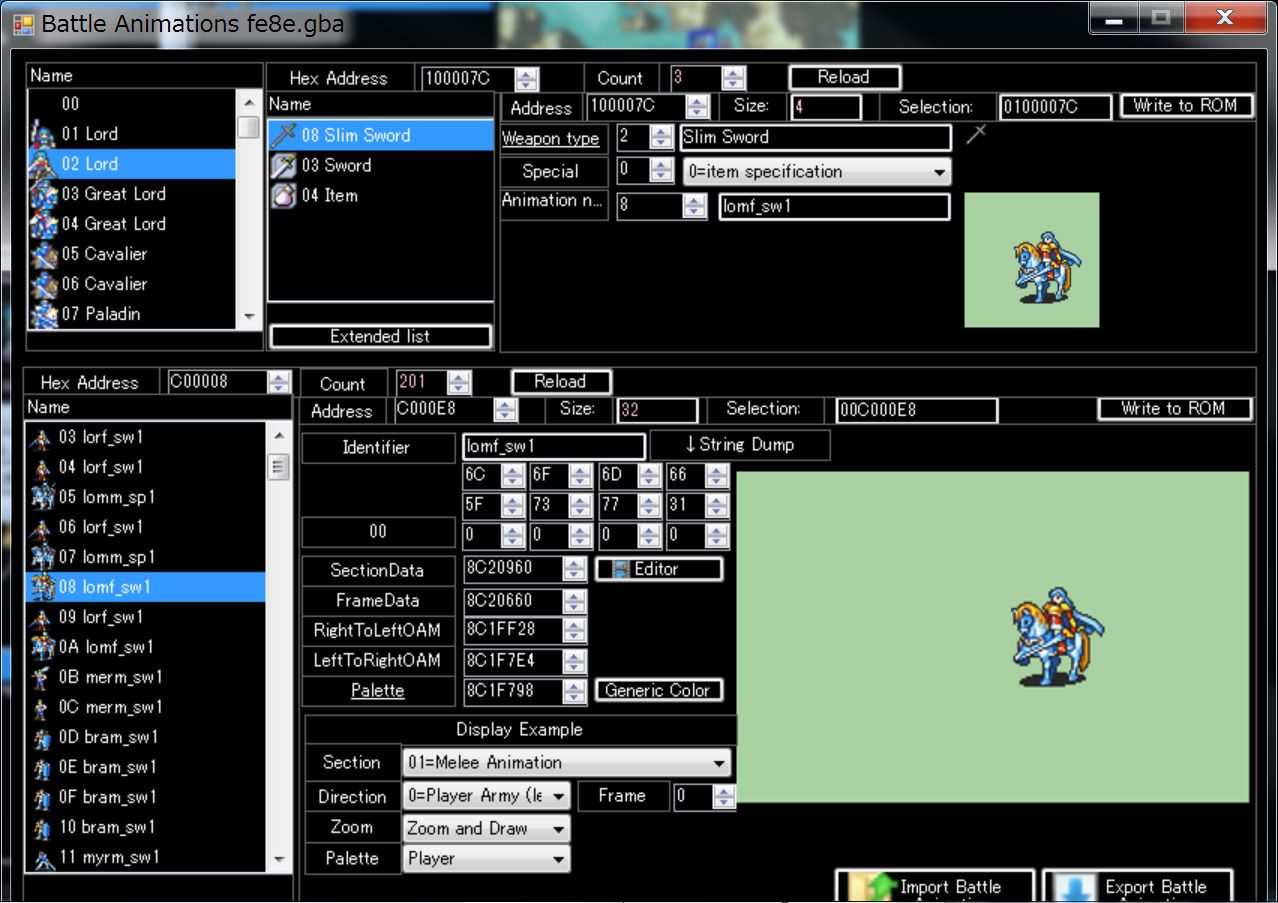
If you only want to display a special animation only for a specific weapon, you can do with the function of vanilla.
For example, please set as follows.
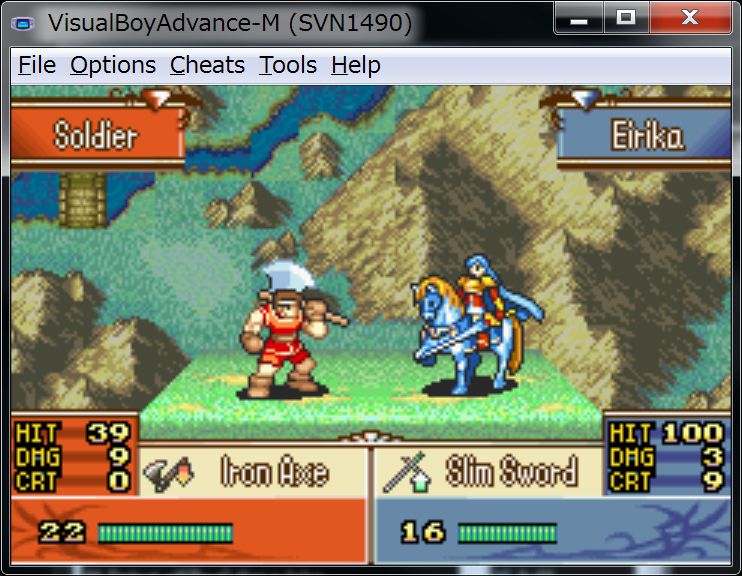
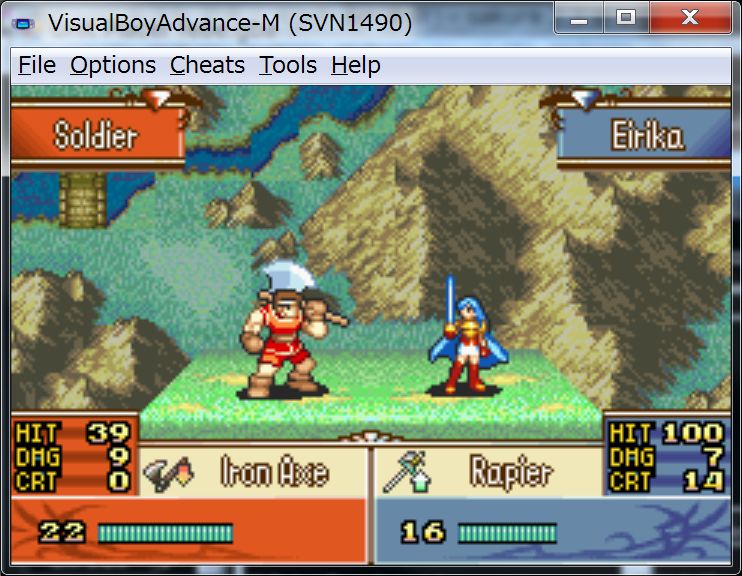
eirika will ride a horse only when equipped with Slim Sword.
I meant the Modern Character Growths (Growth = Character Growth + Class Growth) patch. How do I undo the effects of installing it because uninstalling it doesn’t do anything.
Thank you for explaining this! now it works 
I see.
Please update FEBuilderGBA to the latest version.
If you still have problems that can not be uninstalled, please send me report.7z.
I tested with ver 20180731.23, but I could uninstall it.
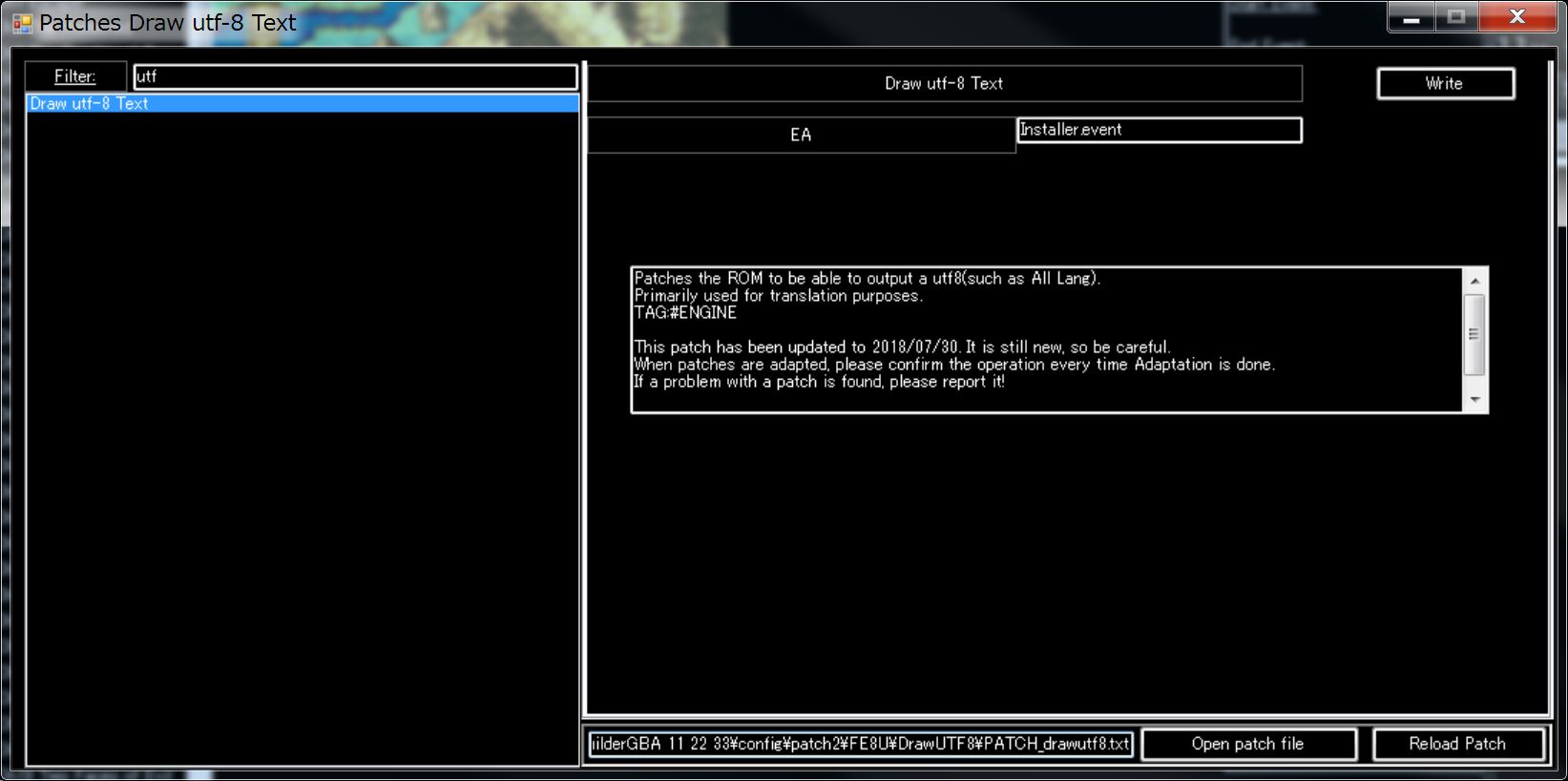
DrawUTF8
This is a patch that displays UTF-8 in FE8U or FE7U.
This patch can theoretically support up to UTF-32.
So you should be able to display all languages on the Earth.
However, since FEBuilderGBA is written in C#, C# has UTF-16 restrictions, it has not been fully tested for UTF-32 yet.
Please use the latest version of FEBuilderGBA (ver 20180731.23 , or later).
Since it is a new patch, if you have a bug please contact me.
How to use.
Adapt the DrawUTF 8 Patch.
Edit your favorite character string.
Let’s change the “Load” of the class name this time.
Let’s change “Load” to the Japanese name “ロード”.
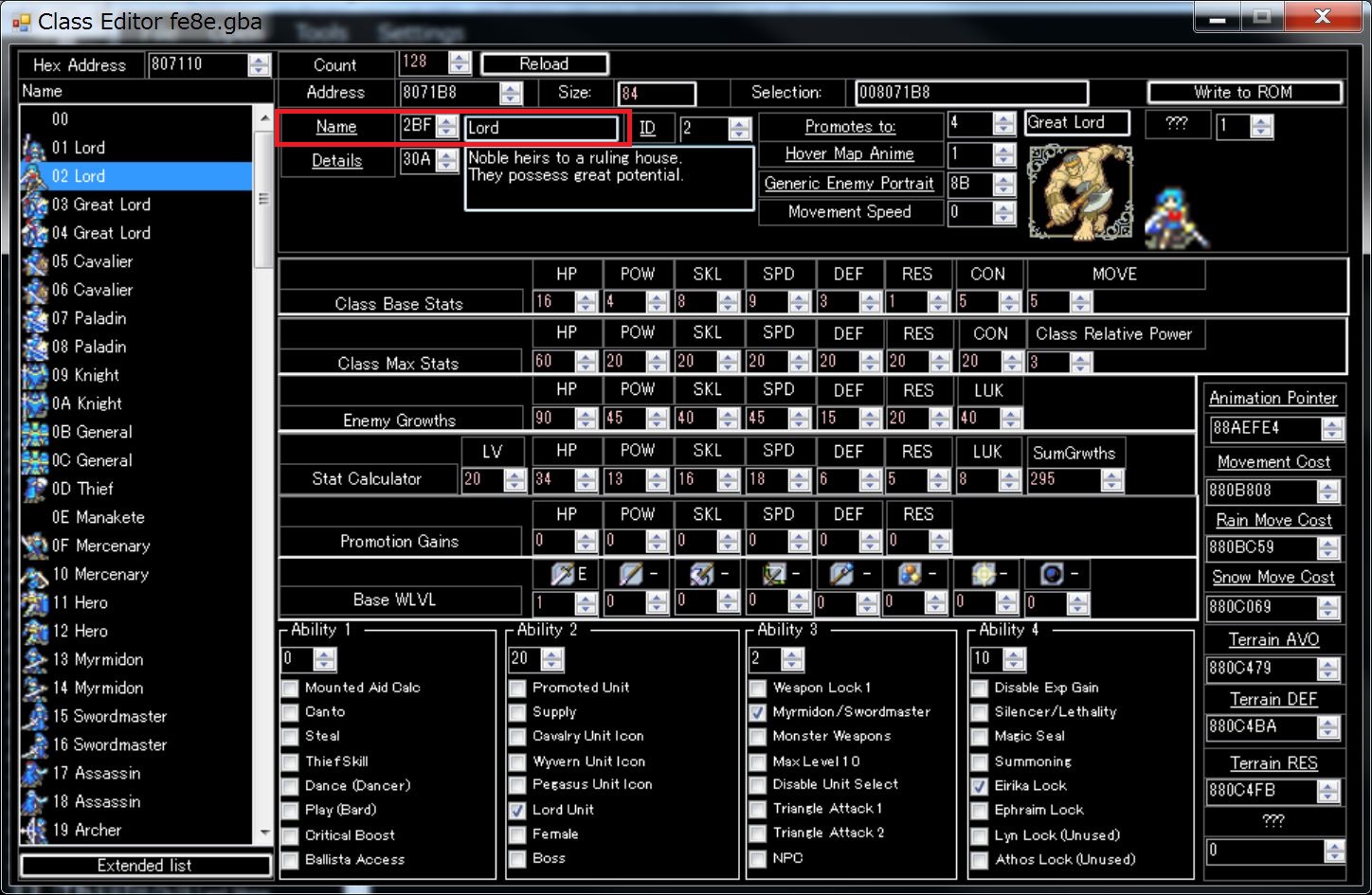

Please apply Anti-Huffman Patch. (It will be displayed only once for the first time)
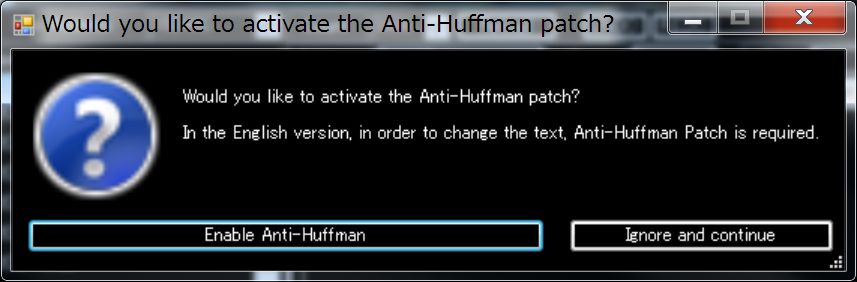
Well, for now let’s start the game by pressing the F5 key.
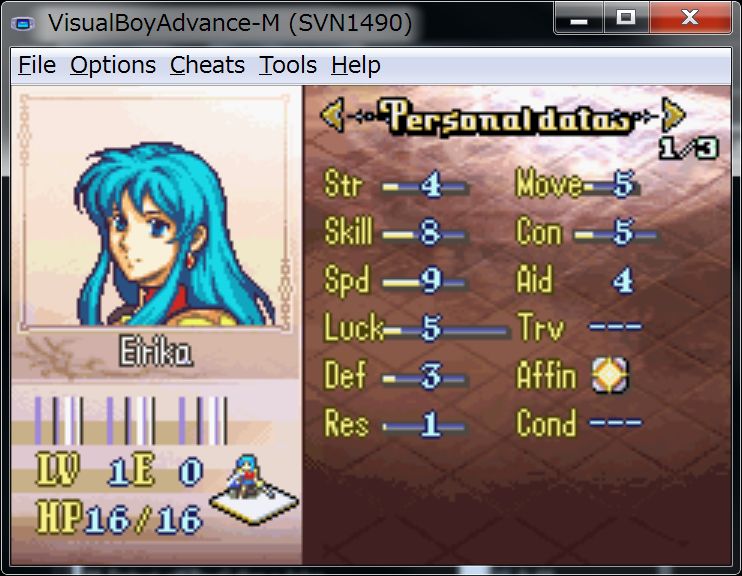
Wow, they are buggy.
This is because fonts do not exist.
Let’s install fonts before posting this image to Amusing ROMhacking Glitches Thread.
There are two ways to install fonts. (There are three practical methods)
Method 1. The easiest way
Menu -> Tool -> ROM translation tool
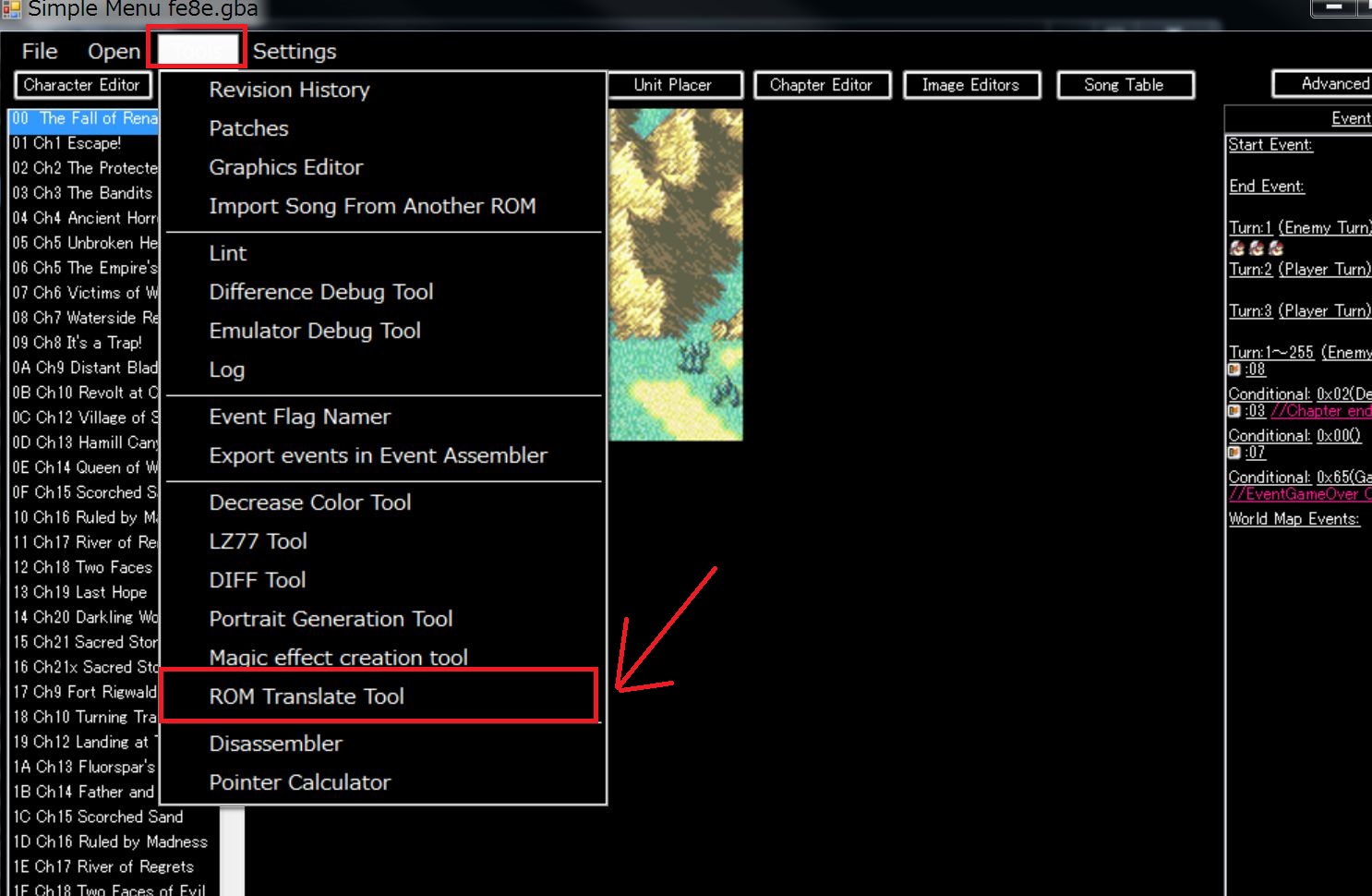
Please press the button on the bottom screen (Import Font) without changing anything.
Automatically creates missing fonts using OS fonts.
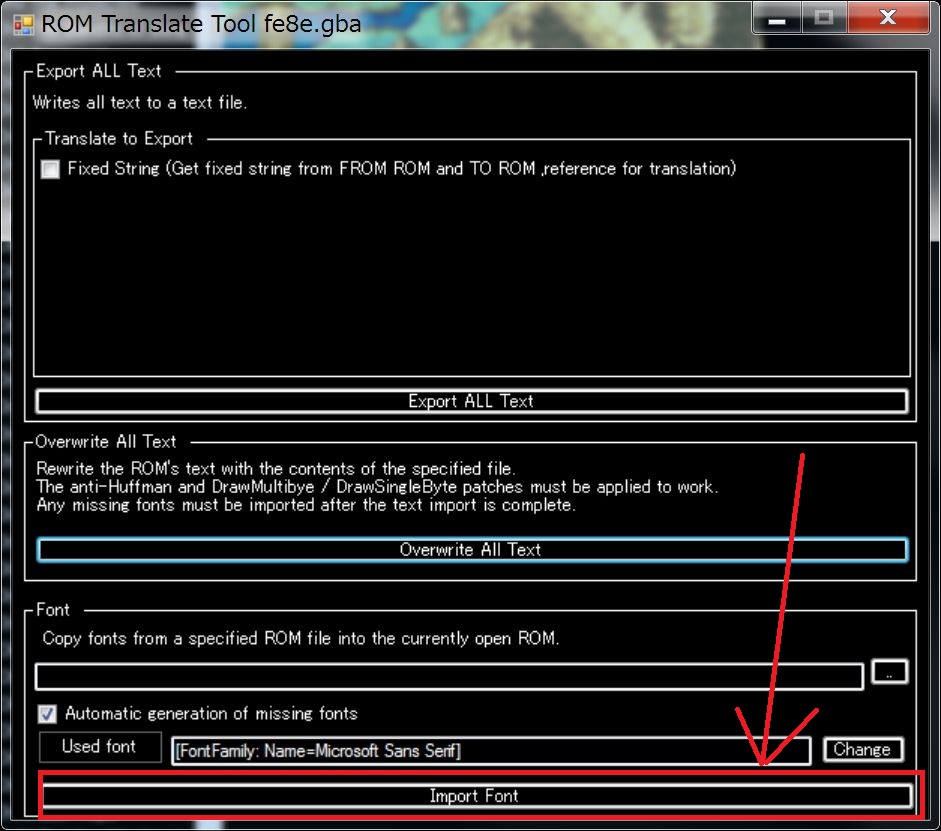
Let’s restart the game with F5 key, again.

This time it will be displayed correctly.
バンザイ! Banzai!
If you do not have Japanese fonts installed, please download the font from google’s notofu project etc.
Method 2. How to define each one manually
From the detail menu, select Font.
Here you can change the font one by one.
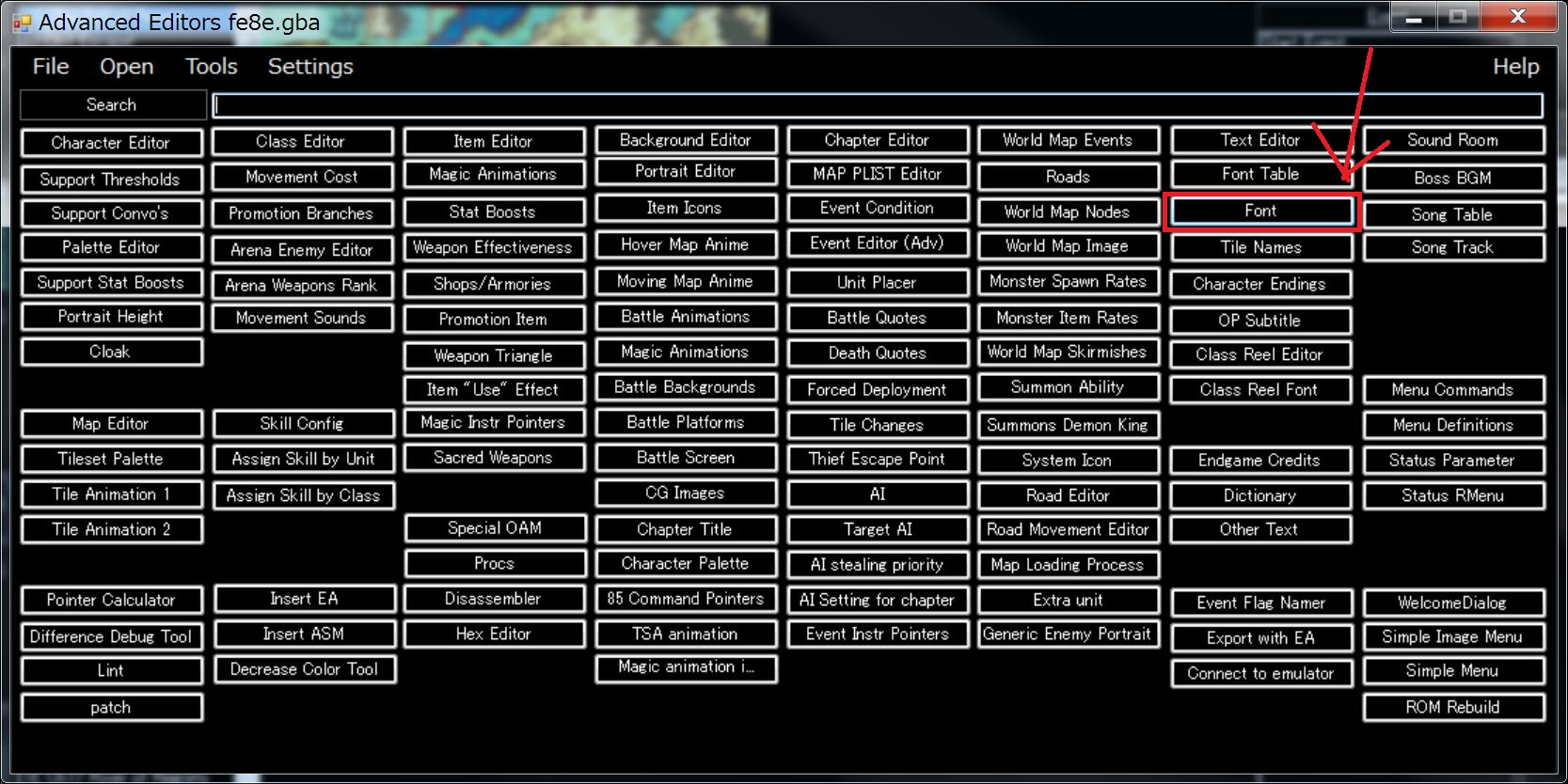
This time, it is a three character string “ロード”, so you need to import it three times.
There are two kinds of fonts, item font and serif font used for dialogue.
The status screen is drawn with item font.
Please search by “ロ”.
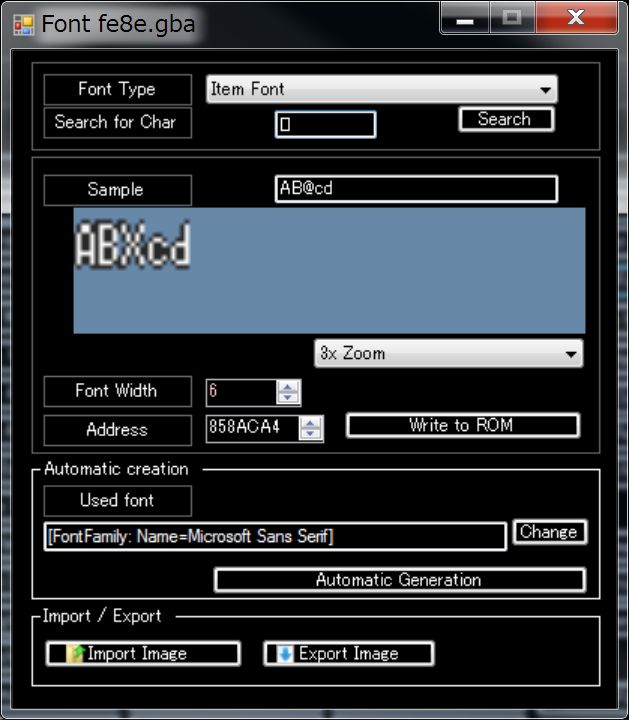
We get an error saying there is no font.
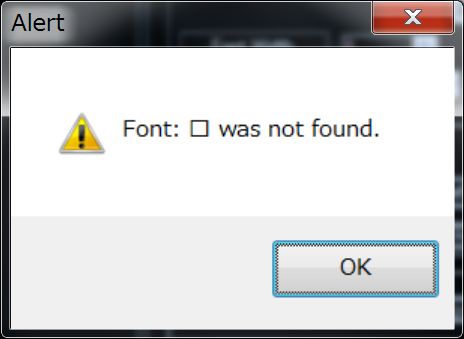
Here, you can draw your own font and import it, but since it is troublesome, let’s create it automatically.
By pressing the Automatic Generation button, fonts are automatically created using OS fonts.

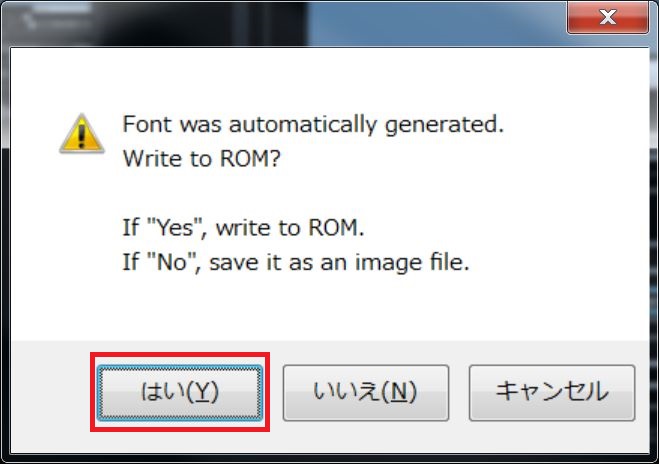
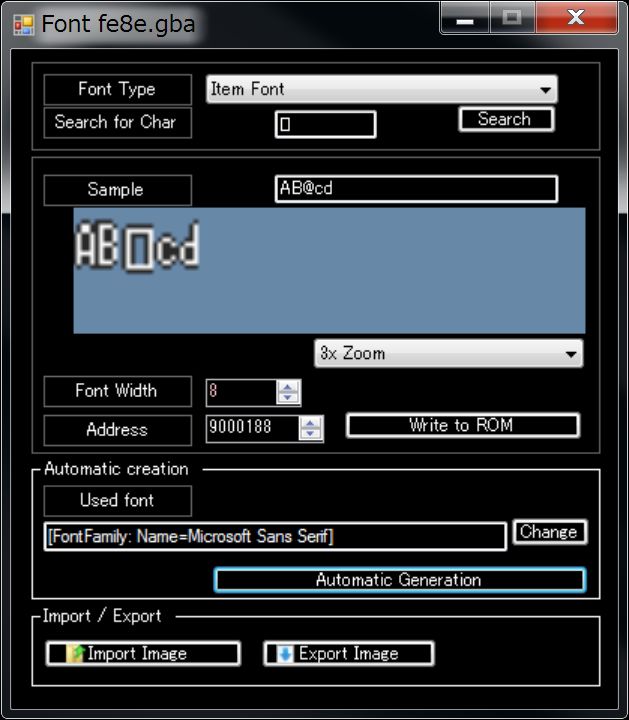
If you do not like the automatically created font, press the Export button and it will be saved as png.
Fonts are treated as 4 color PNG data.
![]()
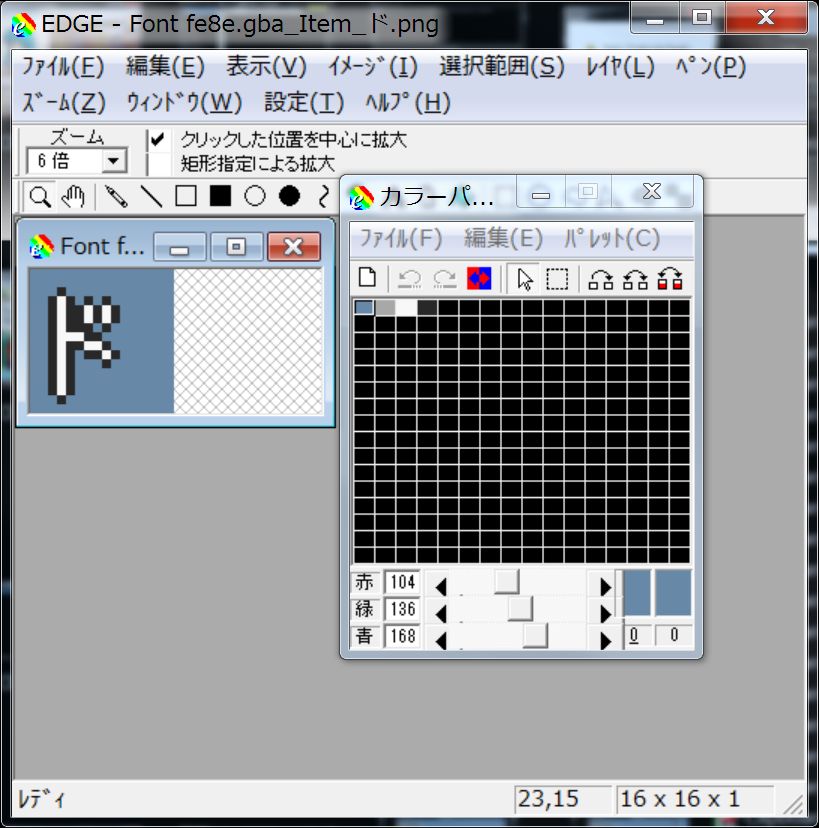
You can now create a font in the “ロ” portion of “ロード”.
Please install fonts for the remaining “ー” and “ド” as well.
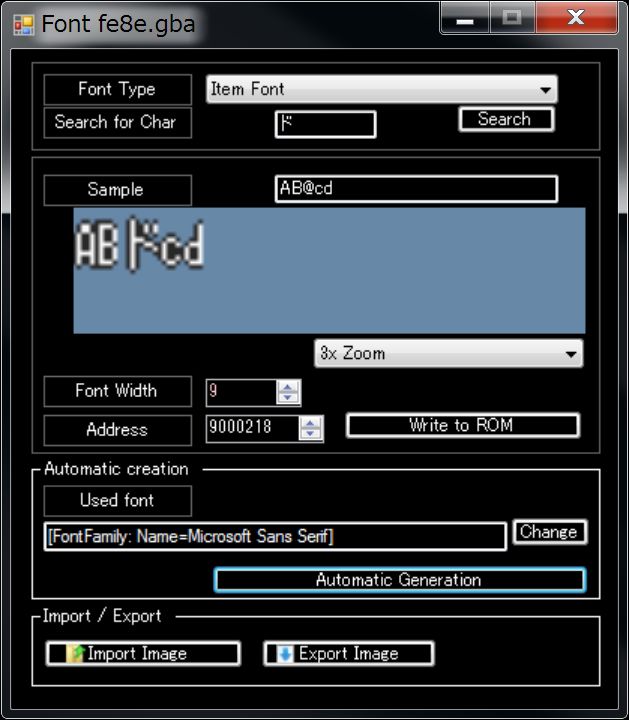
Let’s restart the game with F5 key.
It will be displayed correctly.
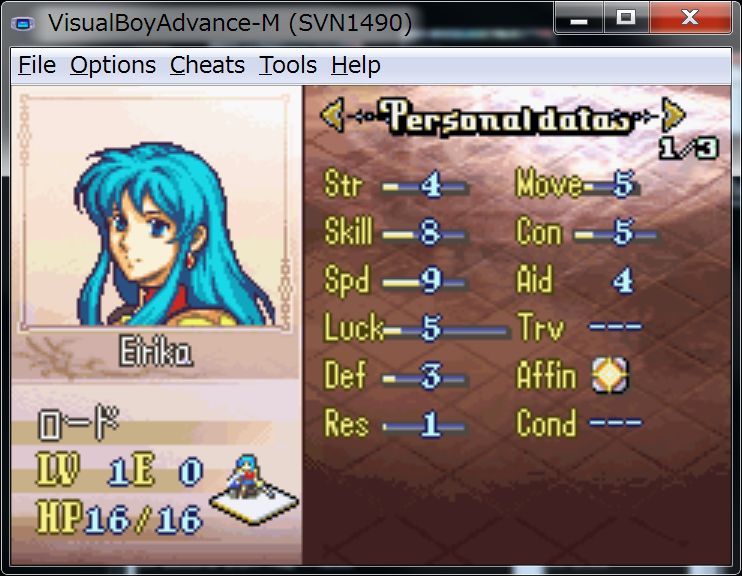
万歳! Banzai \((^0^)/
that’s all.
Now you can now display all languages on the planet in the game.
For FE8J, FE7J, FE6, it is quite difficult to convert to UTF-8 because data has already been created with SJIS character code.
Also, FE8EU and FE7EU are probably difficult because they are made with LAT1.
This is possible because FE8U and FE7U are alphabets that do not conflict with UTF-8.
Below this is contents for fe hackers who are interested in character codes.
The UTF-8 encoding method is not described in this document.
Please see other document or wikipedia etc.
Well, this patch breaks one UTF-8 rule.
In UTF-8, 0x80 must be represented as a character in the middle of multi-byte.
However, 0x80 is used in large quantities in the existing ROM.
For example, @0080@000A [MoveFarLeft]
Therefore, with this patch, only 0x80 ignores UTF-8 rules.
If the beginning of the character code is 0x80, it is evaluated as one letter of the escape sequence.
About the Text data structure.
Character data is stored using UTF-8 text as it is, using Anti-Huffman.
However, as explained above, only 0x80 is used as an exception.
The character string “ロード” is stored as follows.
E3 83 AD E3 83 BC E3 83 89 00 00
This is as follows.
E3 83 AD //ロ
E3 83 BC //ー
E3 83 89 //ド
00 00 //null term.
About the Font data structure.
FE’s font data is hash + list structure for Japanese SJIS.
However, in English-speaking countries and LAT 1, since only a single byte is used, it actually becomes hash.
struct font
{
void* next_pointer; //+0x0 Japanese ROM only. Otherwise it is null.
byte sjis2byte; //+0x4 Japanese ROM only. Otherwise it is 0.
byte width; //+0x5 The width of the font.
byte unk1; //+0x6 Fixed 00.
byte unk2; //+0x7 Fixed 00.
byte bitmap4color[64]; //+0x8 Bitmap 4 colors.
}; sizeof() == 72(0x48)
Therefore, I restored the structure of Japanese hash + list and extended it to UTF - 8.
Also, because there was a vacant byte, I used it to express UTF-32.
uint utf32 = 0xbeefbeef;
byte moji1 = (utf32 & 0xff);
byte moji2 = ((utf32>> 8) & 0xff);
byte moji3 = ((utf32>>16) & 0xff);
byte moji4 = ((utf32>>24) & 0xff);
struct font* font = FontTable[moji1];
while(font != null)
{
if ( font->sjis2byte == moji2
&& font->unk1 == moji3
&& font->unk2 == moji4
)
{// found!
return font;
}
font = font->next_pointer;
}
return NOT_FOUND;
7 Likes
I will fix DrawUTF8 patch.
I’m not confident about the moji 3 and moji 4 sections that are recording in reverse.
This part is always 0x00 0x00 unless to use UTF-32, so I can not test it.
I should not make a strange implementation of the parts that can not be tested.
There was also a bug in FE7U , the length of the speech bubble was not displayed correctly.
I will also fix it.
The update solved my problem of the Modern Character Growth patch. Thanks
1 Like