Bug was fixed in ver 20180128.10.
I mistook the name of the list box.
Thank you for reporting.
I think that the font calculation formula is something different.
It seems that it will take time to fixed.
I hope the people who made FE8CN have left some material, but do you know something?
If you have any material, please tell us the link.
Useful, I can translate 
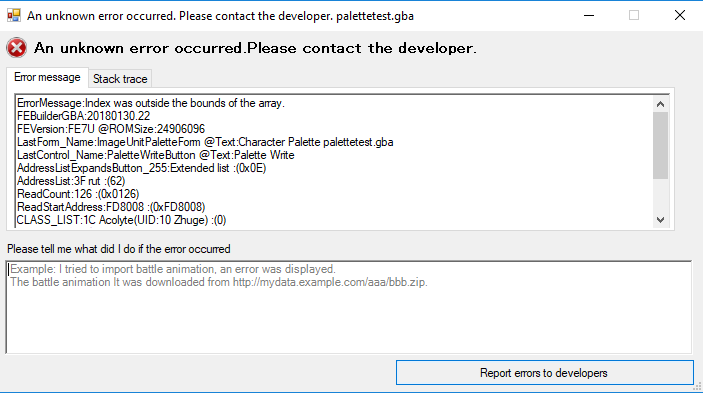
I can not reproduce it.
In my environment, changing the 0x3F rut’s palette does not matter.
How did you get this error?
Please send me an ups patch of ROM you are remodeling.
I can not fix bugs if I can not reproduce the problem.
In order to reproduce the problem, I need your ups patch.
Sorry for the late reply.
Chinese fonts seem to be doing their own processing.
I have not analyzed yet.
Perhaps it is a structure that uses the characteristics of Chinese fonts, but I can not say because I do not understand Chinese.
In FE8J (FE8CN) font search is performed with 0x08003F28 function.
For Japanese, double-byte SJIS is used and a hashed list of SJIS is searched.
Example of searching Japanese SJIS character code in FE
//紋 SJIS(0xE496)
byte sjis1 = 0xE4;
byte sjis2 = 0x96;
dword topaddress = 57994c;
fontlist* p = topaddress + (sjis1 << 2) - 0x100;
while(*p)
{
if ( p->check == sjis2 )
{//found.
//p->width Character width.
//p->bitmap Font image. 4bit color bitmap
return p;
}
//Go to the next list.
p = p->next;
}
struct fontlist
{
fontlist* next; //Next font pointer. 0x00000000 in case of termination.
BYTE SJIS2; //With the 紋 SJIS (0xE496), 0x96 in the second byte enters ..
//If it does not match, it will be a heart as an unknown character without characters.
BYTE WIDTH; //Character width (When drawing the next character, this size is like padding like css to empty this size).
BYTE dummy[2];
BYTE bitmap[64]; //Uncompressed 4 bit bitmap.
};
This is based on the character code property that when SJIS hashes with 1 byte, the amount of data to be searched can be reduced.
In the case of SJIS, the first byte represents a block in the code table, and the next byte can determine the character.
SJIS code table
http://charset.7jp.net/sjis.html
However, this function has been greatly rewritten by FE8CN.
I do not understand why I rewrote it.
Perhaps, They wanted to implement a reasonable search by using the characteristics of the Chinese character code,
Or do they need things like unicode join letters?
I do not know the character of the Chinese character code.
All right. I want to know how to help you 
(If use “Japanese”, I will understand better. )
私は、中国語文字コードのルールを知りたい。
I would like to know the rules of Chinese fonts.
なぜ彼らは、0x08003F28関数を書き換えましたか?
why they changed 0x08003F28 functions?
それは、中国語文字コードを使う上で、書き換える必要があったからだと思います。
I think that it was because it was necessary to rewrite it in using the Chinese character code.
それはなぜでしょうか?
Why is that?
I decided to delete the Japanese file name from the patch directory of FEBuilderGBA.
It seems that patches can not be displayed in some environments with Japanese files.
As a result, the patch directory is changed from patch to patch2.
Delete the old patch directory with the next update.
In patch 2, existing patches are converted into English name files and exist.
Since it will be only ASCII character strings, I think that problems will be less likely to occur.
This patch replacement is handled automatically by the updater, so you do not need to worry about anything.
FE8U is not UTF-8.
This is a unique character code that uses only a part of Unicode’s single-byte character string.
It was supported by ver 20180202.20.
When it was 0x82 - 0xff, unicode characters were displayed.
There is also a character code which is not currently in FE8U, but it is secured larger for those who want to add character font.
ふるいROMですので、翻訳した人も見つからないかも。
そして文字コードは文字の順番みたいものですか。
図のみたいものですか、これは烈火の剣のフオントです。
文字の番号があるけど、でもFE_Builder_GBAでめえるから、役立たないかも。
でもある先輩C言語で文字改造プログラムを作りました、
解読できれば、文字改造に役立かもしれない。
必要あれば、使い方をほんやくできます。

この画像を作るのに使ったプログラムのソースコードをみたいのですが、どこにありますか?
I would like to see the source code of the program I used to create this image, where is it?
文字コードとは、文字をどうファイルに記録していくかを取り決めたルールです。
Character code is a rule that decides how to record letters in files.
中国の文字コードは、GB2312という名前のものだと思います。
I think the Chinese character code is named GB2312.
あなたは、ROMからフォントを持ってきたのではないのですか?
Have not you brought fonts from ROM?
このC#のプログラムでは、Windowsのフォントデータを利用しています。
This C# program uses Windows font data.
私は、あなたがFE7CNのROMから持ってきたものかと思っていましたが、そうではありませんでした。
I thought that you brought it from ROM of FE7CN, but it was not so.
FE7CNのフォントデータの謎は解決されませんでした。
The mystery of FE7CN’s font data was not solved.
おそらく、私は、GB2312について知る必要があります。
Perhaps, I need to know about GB2312.
中国では、GB2312と ASCIIが混在した場合、どう処理していますか?
In China, how do you handle when GB2312 and ASCII coexist?
日本のSJISでは、以下のような判別方法を利用していました。
SJIS in Japan used the following discrimination method.
public static bool isSJIS1stCode(byte c)
{
if (((0x81 <= c && c <= 0x9f) || (0xe0 <= c && c <= 0xfc)))
{
return true;
}
return false;
}
public static bool isSJIS2ndCode(byte c)
{
if (((0x40 <= c && c <= 0x7e) || (0x80 <= c && c <= 0xfc)))
{
return true;
}
return false;
}
私たちは文字列を以下のように処理しています。
We are processing strings as follows.
for(int i = 0 ; i < data.Length ; )
{
if ( isSJIS1stCode(data[i]) && isSJIS2ndCode(data[i+1]) )
{//SJIS CODE
i+= 2;
}
else
{//ASCII CODE
i+= 1;
}
}
中国ではどのような処理しますか?
What kind of treatment will be done in China?
Mr. 7743, can you tell me how to use FEBuilderGBA to add skills to the characters?
@meng You first need to use the Skill Extension SkillSystems patch located under menu “patch”.
Then you will be able from the Advanced Editor to use the Assign Skill by Unit / by Class located at the second column.